> For the complete documentation index, see [llms.txt](https://xiang753017.gitbook.io/zixiang-blog/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://xiang753017.gitbook.io/zixiang-blog/database/qian-tan-nosql-zi-liao-ku-zen-me-xuan.md).
# \[淺談]-NoSQL資料庫怎麼選?
### NoSQL v.s RDBMS
**\[關聯式資料庫(RDBMS)]**: \
是目前很常用的資料庫,完全遵守ACID原則,在任何情況下(A)**都可保持每個Transaction不成功則roll back**、(C)**資料一致性**、 (I)**讀寫不互相干擾**、 (D)**數據永久性**。
然而它只支援垂之擴充,若要應用在大量的資料的時候,就只能透過硬體的升級,如cpu 升級、使用NAS、SAN擴充硬碟資源等。
> A: Atomicity, C: consistency, I: Isolation, D: duration
**\[非關聯式資料庫(NoSQL)]**: \
是目前在雲端服務很常使用的一種型態的資料庫。僅具備BASE原則,(BA)**只保證一定的可用性8**,(S)**不保證在同時有讀寫**時資料是一致的,(E)**資料最終一致的特性**。
**但具備水平擴充、垂直擴充**。換句話說只要同步的增加主機數量,NoSQL能力就會成比例上升,或者直接升級單一資料庫的效能能達到效果。
> BA: Basically Available, S: Soft-state, E: Eventually consistent.
**\[NoSQL v.s RDBMS 使用場景]:**
* RDBMS因具備ACID特性,若需要確保資料在任何情況下都穩定的場景就比較推薦。
* NoSQL比較適合用在雲端服務上,或者對於資料的穩定性不這麼高的使用場景。因為具備水平擴充,因此不會有single failed的問題、擴充的成本相對垂直擴充低。
### 1. \[NoSQL 分類]- 以資料型態分類
主要分為三種,key-value、wide-column、documents的資料型態:
* key-value:
在做簡單的Query會比較快,但如果是複雜的Query就不怎麼方便
**ex: Redis DB**

* document:
也是一種key-value store,只是限制value 的結構為semi-structure,像是JSON等。ex: MongoDB
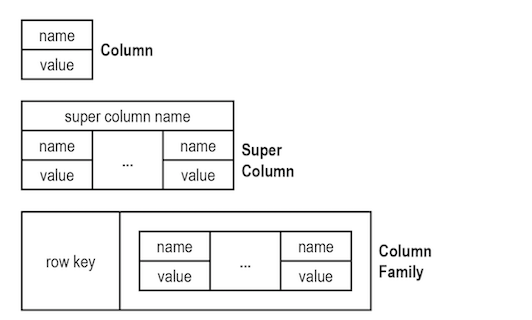
* wide-column:
透過多個raw、column進行存取,將要的資料拆解成小資料,然後進行組合。最後可以透過column key 或者row key 進行關聯搜索。**好處是有效的壓縮資料以及取用同一等級的資料集相當方便。**
### 2. \[NoSQL 分類]- CAP (Consistency, Availability, Partition Tolerance)
Consistency: 讀寫都會遵循Atomicity原則,Availability: 在non-failing node的時候 Client 讀、寫都能正常運行,Partition Tolerance: 在cluster 狀態下,node 之間的網路不穩的狀態下,還能夠維持availability。
從上述CAP中,一般資料庫不可能同時達到,因為在Available的情況下,Consistency與Partition Tolerance是互相矛盾的。(**cluster node不能互相溝通時,不能保證資料的一致性**),因此大致的分類有 AP、CA、CP:
* AP: 不管是在 single-node 或者是 cluster,只有要 node 可用就能持續運作
* CA: 在沒有任何的例外下,都是可用並保證資料的一致性。
* CP: 在 node 之前不穩定的時候不接受 request。
### 3. \[NoSQL 分類]- Sharding
傳統的RDBMS依賴 shard-disk 架構增加data repository的容量,NoSQL則是可透過 Sharding 技術做到。主要有分三種: Ranged Sharding、Hash Sharding、Entity group Sharding方式。
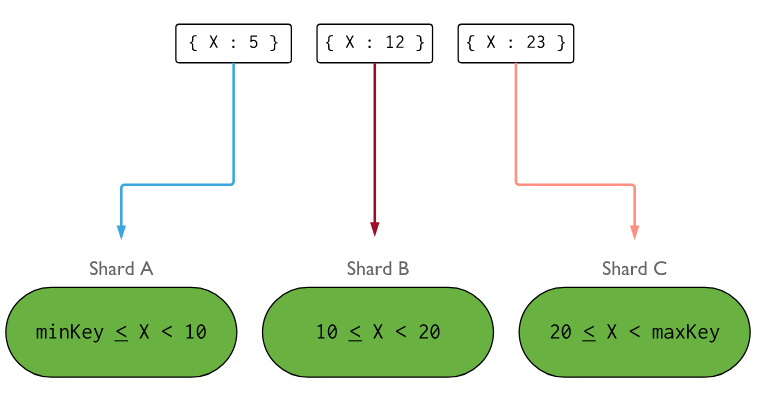
* Ranged Sharding:
主要是利用編號的方式進行分群,如下圖當x>20的時候,分配給shard C。
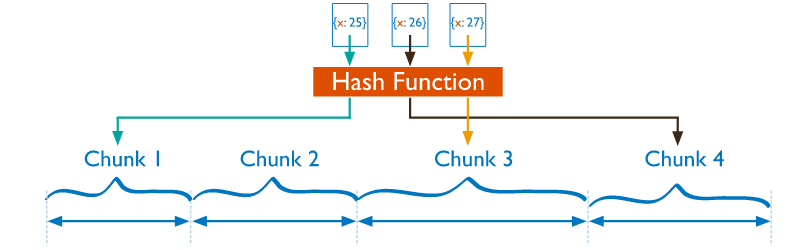
* Hash Sharding:
透過 Hash 的方式進行分群,分佈起來會比較均勻。Ranged Sharding 則有可能會有分佈不均的問題。
**-> Consistent Hashing:** 使得每一個chunk 存資料的機率都一樣。
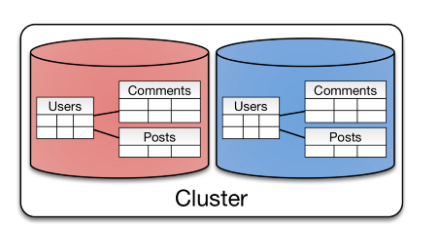
* Entity Group Sharding:
將有關聯的欄位做Sharding,這樣一來在搜尋上、資料一致性上都會來的更有保障。
### 4. \[NoSQL 分類]- Replication
在大型應用場景域中,幾乎會遇到各種裝置在已知例外、未知例外的情況下導致節點失靈的問題,然而Replication就是屬於用於解決問題的解法。透過將資料備份的方式使得即使失靈,也不影響運作。
* Master and Slave: 當client將資料注入Master 資料庫,然而Master 會自動透過Replication,將slave更新。
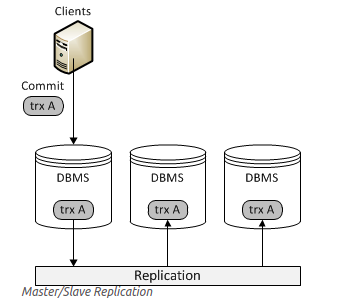
* Multi-master Replication: 類似Master and Slave 的方式,Master 主機同時也是slave角色,當其中一台Master 更新的時候,其他Slave也會同時更新。
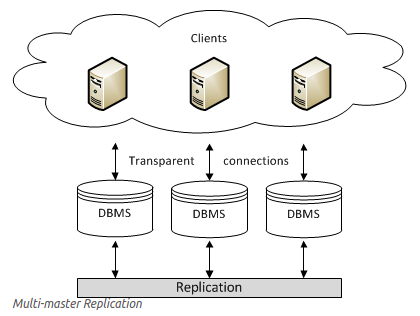
Replication 的動作可分成 Eager (sync)、Lazy(async):
* Eager Replication: 在同步下,當資料注入的時候,全部的node 都會具備相同的資料,但缺點是在效能上必須有所犧牲。
* Lazy Replication: 在非同步下則是透過被動的方式,在一段時間後才會同步完成。
### 5. \[NoSQL 比較表]
| Dimension | MongoDB | HBase | Cassandra | Riak | Redis |
| ----------------------------------- | ------------------------------ | ------------------ | ------------------ | ------------------ | ------------------- |
| **Data Structure** | Document | Wide-column | Wide-column | Key-value | Key-value |
| **CAP** | CP | CP | AP | AP | CP |
| **Disk latency per get by row key** | Several disk seeks | Several disk seeks | Several disk seeks | One disk seeks | Memory |
| **Write performance** | High(I/O) | High(I/O) | High(I/O) | High(I/O) | super High (Memory) |
| **Sharding** | Hash、range-based | range-based | consistent hashing | consistent hashing | hash |
| **Replication** | Master-slave,snyc configurable | File-system-level | consistent hashing | consistent hashing | Async master-slave |
### 6. 常見資料庫推薦與適合場域
下圖為文獻中的分類表\[1],給出不同的需求而所適用的資料庫。從Query 的角度分類,\[(左)搜尋速度快、(右)複雜的搜尋],進而對於抓取資料的大小、容量(volume)進行分類,最後則是以資料庫的特性進行分類。
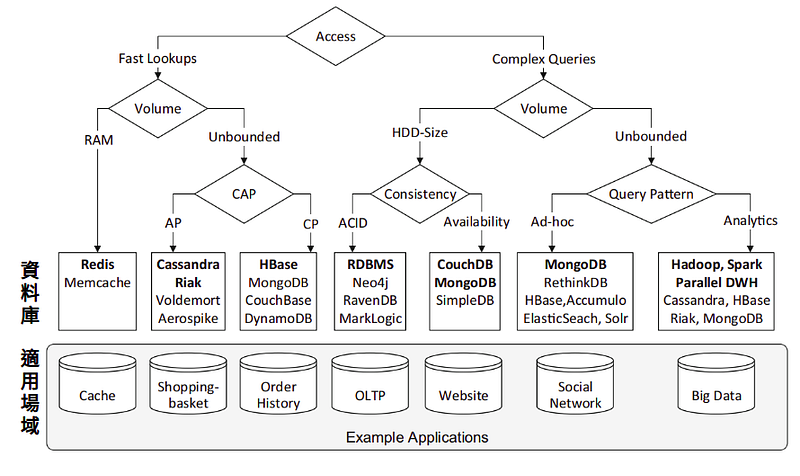
> 專有名詞:\
> 1\. Unbounded: 指的是在分散式架構中,可搜尋的容量為無限 \
> 2\. HDD-Size: 之的是在single node 情況下,可搜尋的容量為硬碟容量 \
> 3\. Ad-hoc: 即時查詢,如sql中的 select ..from aDB where \[condictions..]\
> 4\. Analytics: 只的是在query 的時候可具備資料分析的能力 \
> 5\. OLTP((online transaction processing): 網路交易process
### 參考資料
\[1] Gessert, Felix, et al. “NoSQL database systems: a survey and decision guidance.” *Computer Science-Research and Development* 32.3 (2017): 353–365. \
\[2] \
\[3] \
\[4] \
\[5] \
\[6]